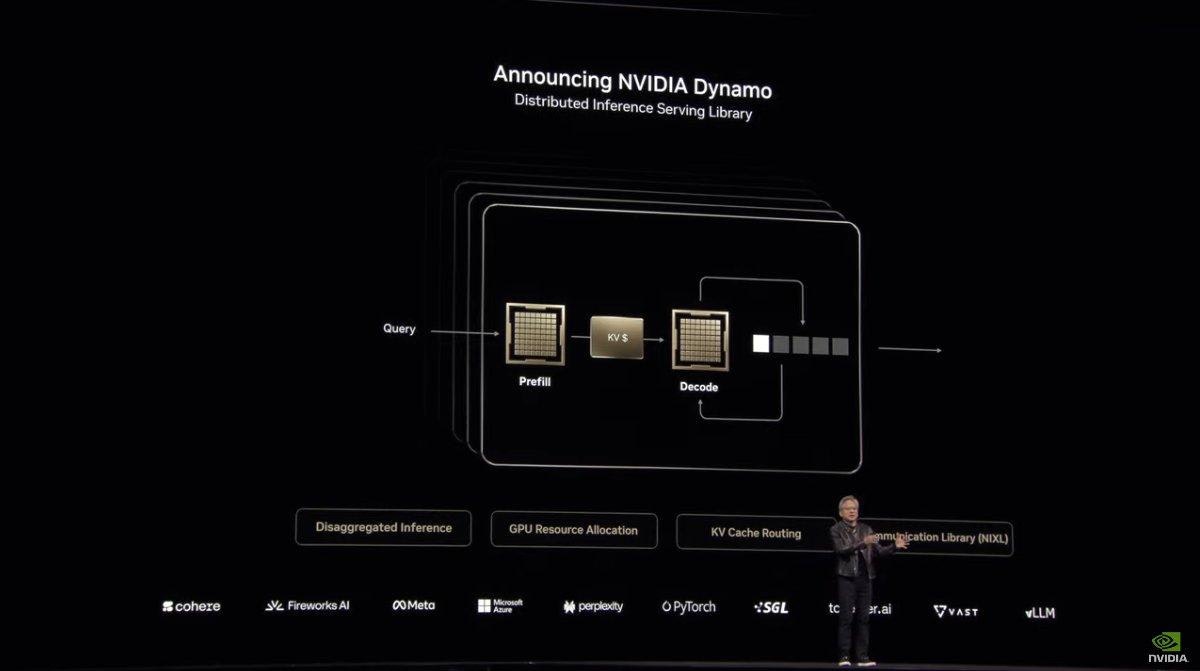
NVIDIA在GTC 2025不仅公布Blackwell Ultra加速运算GPU,还宣布对于当前资料加速运算产业相当重要的开源AI推论服务软体NVIDIA Dynamo;NVIDIA Dynamo是作为协调与加速数千个的GPU的推论通讯,利用分散式运算特性于大型语言模型的处理与产生分配到不同的GPU,可针对特定需求单独将每个阶段最佳化;NVIDIA Dynamo不仅完全开源,还支援包括PyTorch、SGLang、NVIDIA TensorRT-LLM和 vLLM,企业、新创与研究人员可使用热门的AI框架进行部署,同时实现分散式推论,可提升AI工厂(AI Factory)服务的性能、缩减回应时间与降低模型服务成本。
NVIDIA Dynamo即日起以完全开源形式于GitHub开放开发者存取使用,同时也将在NVIDIA NIM微服务提供,计画后续获得NVIDIA AI Enterprise软体平台资源提供企业更高层级的安全性、支援与稳定性。
▲NVIDIA Dynamo能使具备大量GPU的AI工厂更有效率的以分散式运算方式提升性能,并针对GPU、记忆体等资源进行协调
NVIDIA Dynamo定位在NVIDIA Triton Inference Server的后继者,旨在为AI工厂提供高效的测试阶段扩展运算解决方案,能为以执行推论AI的AI工厂提供最大化的词元收益,透过针对分散式运算架构进行海量GPU的加速与协调,透过整合多项功能提高传输量与降低成本,具备动态新增、移除与重新分配多个GPU资源的能力,可有效率的将大型语言模型的处理与生成阶段分配到不同GPU执行,并可针对特定需求将每个阶段更有效的最佳化,可在AI工厂的大型丛集精确定位特定GPU减少回应运算与路由查询,还具备将推论资料卸载至成本更低的记忆体与储存装置,并于需要时快速取得,使AI工厂的大量GPU能最大化资源使用率。
NVIDIA Dynamo将推论系统从先前请求中储存在记忆体的「知识」(KV快取)映射到丛集的数千个GPU,接着将新的推论请求转移到知识相符最高的GPU,可避免消耗资源重新运算,同时释放GPU回应新的输入需求。NVIDIA Dynamo包含四大创新技术,包括可动态增加或移除GPU的GPU规划器,可感知大型语言模型并在大型GPU丛集引导请求的智慧路由器,还有经过推论最佳化的低延迟通讯函式库,与不影响使用者体验智慧进行资料卸载货重新载入至更低成本的记忆体与储存的记忆体管理器。
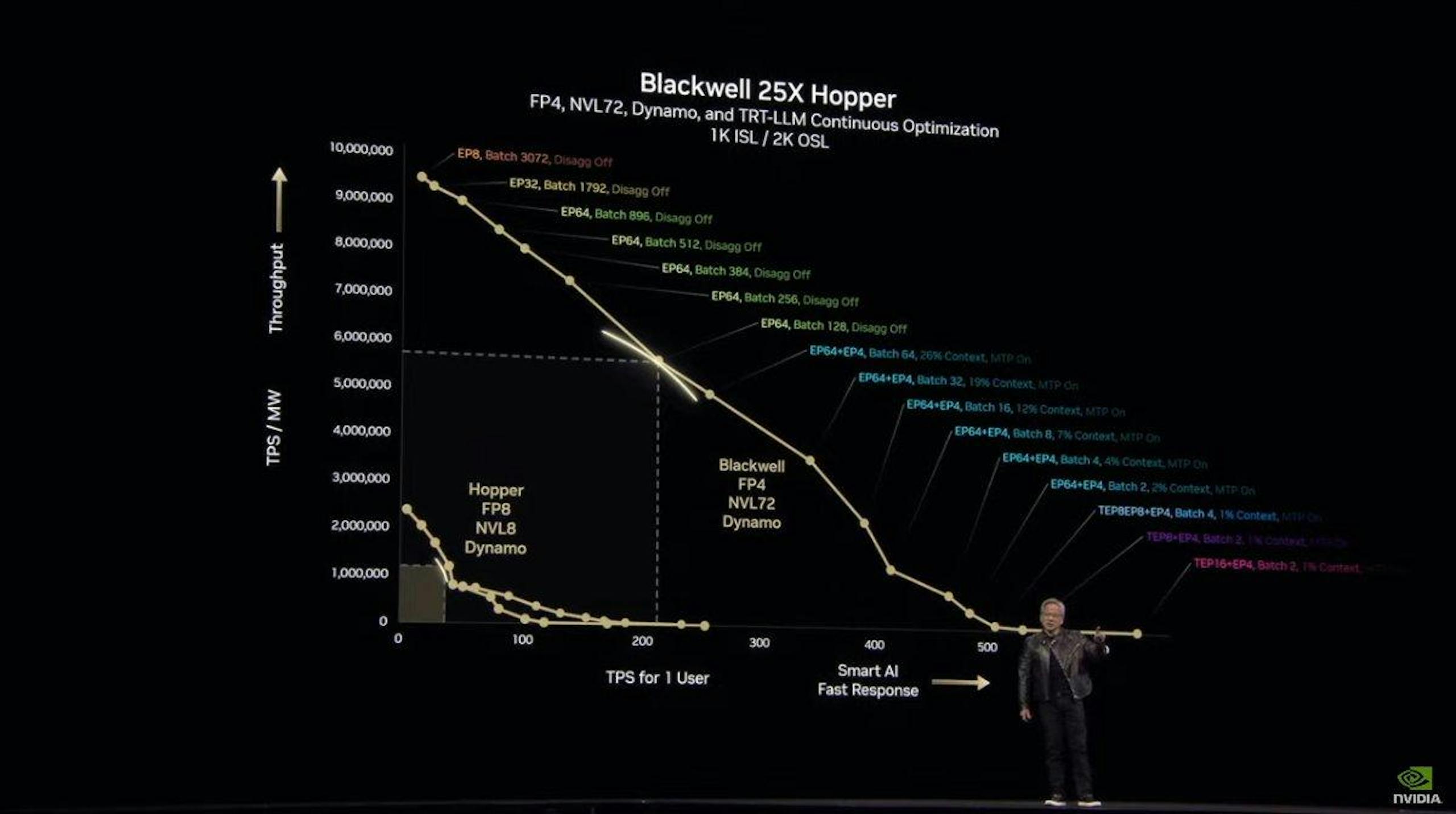
NVIDIA执行长黄仁勋表示NVDIA Dynamo不仅能使新一代的Blackwell架构的AI工厂受益,基于大量Hopper GPU的AI工厂也同样能够受益,然而由于架构的世代落差,Blackwell能够获得更显着的效能提升。




发表评论 取消回复